Pandas is a widely used tool within Python that helps in data manipulation and analysis. My first introduction into Pandas was while working on a project in the Wilke Lab at UT Austin when developing an evolutionary program (This project can be found under the “Projects” tab on the website). Without this package, the reading, writing, and rearanging of files would have been much more difficult as Pandas takes many of its tools from popular R functions. This makes it much easier to manipulate data into the format that is needed as many of the functions are intuitive and quick to learn! That is what makes R such a great programming language. But I will talk about that more in my next blog post. Before we start discussing how to manipulate data in a dataframe, we first need to know what a dataframe looks like. Here is an example of a dataframe obtained from geeksforgeeks.org:
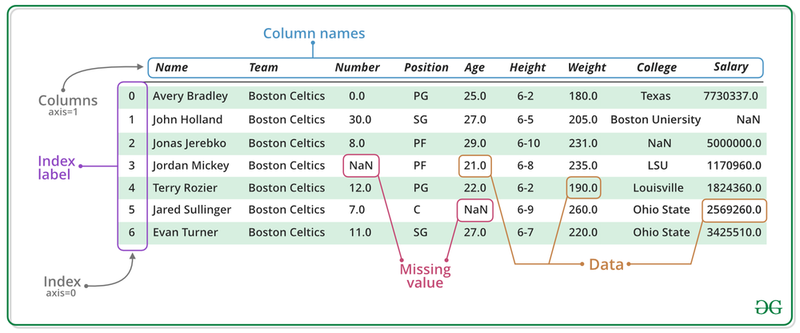
Dataframe Example
One life-saving attribute that Pandas has is the ability to remove the need for loops when trying to manipulate data. Traditionally in Python, data manipulation would have been done with a variety of loops that would parse through the data and shape the rows and columns into the design the user wanted. However, when Pandas was introduced, the need for loops were no more! It took a complicated process of iterating through a table manually and simplified it by having to just use a function that would alter the dataset’s design. Pandas also made it easier to compare data from different datasets as the user could format both datasets to contain a similar design and then find differences between each cell within the sets being analyzed.
An example of using Pandas in a program can be shown in the project that I previously mentioned. The code is located on GitHub and is open-sourced for anyone that would like to have a crack at it! One aspect I wanted to point out was that when importing the Pandas package into Python, the norm is to import pandas as pd so that the user does not have to type out pandas every time they wanted to call a function within that package. Lastly, I wanted to provide an example of how to use pandas and list some of the most important Pandas functions below with a brief description of each one so that it can help give an idea of some of the uses of Pandas:
- melt() - The dataframe is pivoted to go from the wide format to the long format
import pandas as pd
df = pd.read_csv("~/Documents/SDS 348/mlb.csv")
pd.melt(df)## variable value
## 0 Player Mike Trout
## 1 Player Josh Donaldson
## 2 Player Adrian Beltre
## 3 Player Michael Brantley
## 4 Player Jonathan Lucroy
## 5 Player Alex Gordon
## 6 Player Anthony Rendon
## 7 Player Giancarlo Stanton
## 8 Player Andrew McCutchen
## 9 Player Robinson Cano
## 10 Player Jason Heyward
## 11 Player Jose Bautista
## 12 Player Jose Altuve
## 13 Player Steve Pearce
## 14 Player Jhonny Peralta
## 15 Player Kyle Seager
## 16 Player Juan Lagares
## 17 Player Russell Martin
## 18 Player Ian Kinsler
## 19 Player Troy Tulowitzki
## 20 Player Jose Abreu
## 21 Player Yasiel Puig
## 22 Player Howie Kendrick
## 23 Player Todd Frazier
## 24 Player Josh Harrison
## 25 Player Victor Martinez
## 26 Player Buster Posey
## 27 Player Adam Eaton
## 28 Player Brian Dozier
## 29 Player Starling Marte
## ... ... ...
## 1870 WAR 3.5
## 1871 WAR 3.5
## 1872 WAR 3.5
## 1873 WAR 3.4
## 1874 WAR 3.4
## 1875 WAR 3.4
## 1876 WAR 3.4
## 1877 WAR 3.4
## 1878 WAR 3.4
## 1879 WAR 3.4
## 1880 WAR 3.3
## 1881 WAR 3.3
## 1882 WAR 3.3
## 1883 WAR 3.3
## 1884 WAR 3.2
## 1885 WAR 3.2
## 1886 WAR 3.2
## 1887 WAR 3.2
## 1888 WAR 3.1
## 1889 WAR 3.1
## 1890 WAR 3.1
## 1891 WAR 3.1
## 1892 WAR 3.1
## 1893 WAR 3
## 1894 WAR 3
## 1895 WAR 3
## 1896 WAR 2.9
## 1897 WAR 2.8
## 1898 WAR 2.8
## 1899 WAR 2.8
##
## [1900 rows x 2 columns]pivot_table() - The dataframe is altered into a spreadsheet style format
merge() - Combine two dataframes with one another based on a common variable
unique() - Only show the unique values in a certain row or column
isna() - Determine if there is a NA value in the dataframe
However, these are only a handful of useful functions in Pandas but more can be found using the Pandas documentation that can be found here: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html.